CAST consolidates a unique database made of 94M+ Open Source components and 9B+ file fingerprints. This article details the concept and steps in Highlight to automatically retrieve the true origin of your source code, whether it is for license compliance, vulnerability or obsolescence verification.
How we crawl Open Source and feed our database
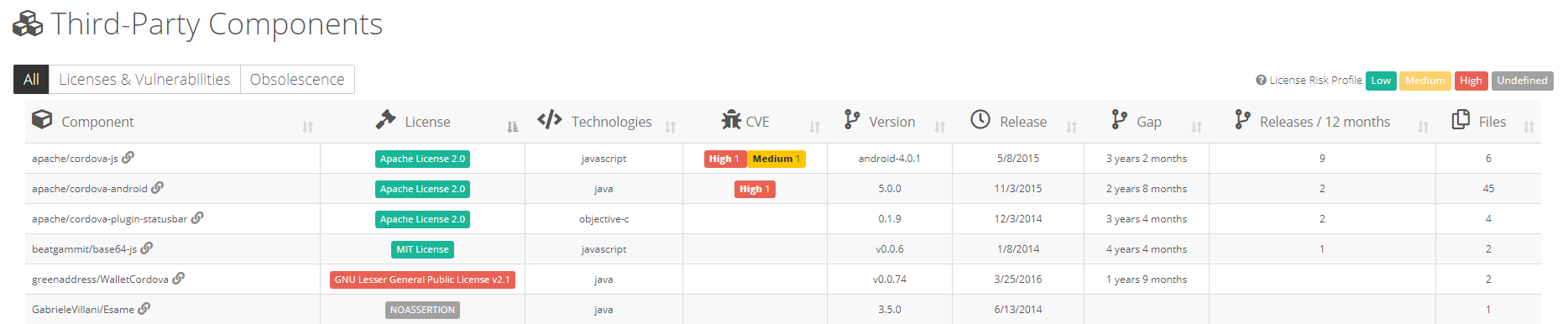
Highlight’s Software Composition Analysis features leverage exclusive patents that CAST has recently acquired to detect the presence and the origin of third-party components in your source code. While this information is useful for vulnerability identification and IP & license compliance, it is important to understand how the overall mechanic works.
To constitute our knowledge base on Open Source, we continuously crawl the different platforms, whether it is for source code (currently supported: Github, GitLab, Salsa Debian, Framagit) or packages/binaries (currently supported: Maven Central, NPM, NuGet, PyPi, Packagist, RubyGem).
The crawling consists of:
1. Cloning a copy of an open source component, inluding all its versions, revisions, commits and files (.java, .js, .jar, .dll, .xml, .md… all files in fact)
2. Starting from day 1 of the project (i.e. the very first version in chronological order), we compute a unique key for each file (using the standard SHA256 secure hash algorithm from NIST) associated with its creation timestamp: these are fingerprints. In other words, if a given file is not modified across the project timeline, its fingerprint will remain the same. As you can understand, as soon as this file is modified (new line of code, instruction, comment, etc.), a different fingerprint (with the modification timestamp) will be computed.
3. All component fingerprints are stored in a database along with the information of version and component meta data (version number, release date, component name, license, origin platform URL, technology, project metrics such as total number of forks, contributors, etc.).
Note: For the time being, forked projects are not considered. Also, the files that have been committed to the MASTER branch of the component but not yet released in a version are not fingerprinted. Who would even include MASTER files into a business application as we all know that this branch is generally a working version which is not necessarily tested, reliable, etc.?
Example of the SHA256 fingerprint of Apache Log4J-core 2.8.2 JAR package available from Maven Central, pushed on 4/2/2017:
10ef331115cbbd18b5be3f3761e046523f9c95c103484082b18e67a7c36e570c
4. Before inserting any fingerprint in the database, the system checks if the same fingerprint has been found previously in the database but linked to another component. If that’s the case, the system retains only the oldest fingerprint based on its timestamp (commit date if it’s a source repository, push date if it’s a package archive).
Why it is important to check temporal anteriority
When you decide to use an Open Source component within your application, you don’t know much about its origin, except perhaps if it’s a fork from another component. However, traceability of what composes your software is key when talking about business applications . It can be the case from a vulnerability standpoint (e.g. a malicious file somewhere in a repo that makes your whole application vulnerable), but that’s especially true when legal & license compliance concerns come into the game.
For instance, when you use a UI Javascript/CSS component under MIT license that itself copy/pasted a couple of stylesheets and scripts directly from an old repository under GNU GPL 3.0. While you would probably have missed this important information with classic SCA tools, the temporal analysis spots this license inheritance right away.
What happens at the scan level of your application?
Whether you use the command line or the local agent to scan your application source code, Highlight computes SHA256 fingerprints of your files, using the same algorithm than the one used by the Open Source crawlers. These fingerprints are stored in the result CSV files produced by the analyzers. Because a binary file (.jar, .dll, etc.) is not a type of file that Highlight parses in depth, binary files are detected in parallel and fingerprinted in a separate result CSV (BinaryLibraries.csv).
Once your results have been uploaded to the Highlight platform, fingerprints are checked against the SCA database to determine matching occurrences across billions of fingerprints and millions of projects. Then, this information is aggregated at the component/version level in the Highlight dashboards.