
How to configure a Keyword Scan for GDPR (or anything else)
What’s GDPR
According to Wikipedia: “The General Data Protection Regulation (GDPR) is a regulation in EU law on data protection and privacy for all individuals within the European Union and the European Economic Area. It also addresses the export of personal data outside the EU and EEA areas. The GDPR aims primarily to give control to citizens and residents over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU.”
Concretely speaking, it means that organizations will have to know if their applications read, process or store Personally Identifiable Information (PII) data of EU-based users, in order to set up the appropriate actions (register the application, declare a Data Processor, qualify the nature and purpose of data collection, modify the application behavior to ask users whether they consent to share their data or not, etc.).
What and why we need to scan the code
According to the GDPR regulation, organizations now have to know if their applications are processing PII data. This is something quite obvious and easy to determine if an application is connected with a central database which holds tables or columns like “first_name”, “email_address”, “social_security_number”, etc. But in Software, nothing is obvious anymore.
First, applications and databases don’t necessarily have a 1:1 ratio. You may have a few central databases that are accessed by hundreds of apps. Then, GDPR is not only about identifying the databases you have and putting them in the GPDR process. This verification also needs to be done at the application level.
Secondly, applications can manipulate PII data without any database. As today API, JSON, web and micro services are the norm, meaning that a piece of source code can read, process and share data with other components without having a clue about the database that initially stored it. A small script cooked by your HR department read LinkedIn’s API to hire the best profiles? There is a risk that it manipulates PII data, at least names, location and profile pictures.
Fortunately, developers love code they can easily read and maintain: 99% of the time they call their classes, methods, parameters with names that are not obscure (e.g. getCustomerName, updateProfile($CreditCardNumber) etc.). As a result, it is possible to approximate (if not determine) that an application processes PII data by scanning its source code and counting occurrences of PII-related keywords. Scanning code to search for patterns? That’s exactly where Highlight comes into the game.
How to configure a Keyword Scan
The Keyword Scan feature works with our command line and takes the path to your keyword configuration file (–keywordScan “path/to/your/file.xml”). This file will tell the analyzers in a structured way what to search during a code scan. Its structure is detailed below:
- UserScan: the root node that contains the configuration.
- keywordScan: the main node for a keyword topic. You can indicate a name and a version (e.g. name=”GDPR” version=”1.2″). You can have multiple topics in a single configuration file as you may want to search for GDPR-related keywords but also keywords for licences, specific unauthorized functions, other regulation tags…
- keywordGroup: the node that will search in code for a keyword or a set of similar keywords (e.g. “social security number”, “ssn”, “social security nbr”, etc.). For each keyword group, you can define a specific weight (for instance, in a GDPR context, a passport number will weigh more than a firstname) and search options such as case sensitivity or full vs. partial word-matching. keywordGroup also allows users to define specific places (search scopes) into a source file (all, code, comment, string).
- keywordItem: one of the search element. You can have multiple items for a given keyword group.
- patternGroup: this node is meant to support more sophisticated search within file content and/or path/file names, allowing you to combine logical conditions (typically AND and OR) through the verification of a formula (see below).
- search: within the patternGroup node, you can specify a pattern, defined by an identifier, whether it is case sensitive or not, full or partial word search. You can search for specific <content> (typically a string) or <filename> (where wildcards are accepted like *.xml) or even <regexContent> (regular expression). Note that <filename> is mandatory.
- formula: this element is mandatory within a patternGroup as it verifies the logical condition of the different searches altogether. You can use AND and/or OR logical operators as well as parentheses to combine searches. Note that all declared search IDs should be used in the formula (otherwise, just don’t create them).
Your final configuration file would look like this. We just added an example of a pattern group for spotting malicious NPM packages, as the keyword scan can work on different topics during the same scan.
A more complete sample XML file can be downloaded from here as well as the associated XML model.
What is the difference between keywordGroup and patternGroup?
You probably noticed that you can use two modes to search things with the Keyword Scan feature.
- keywordGroup: this mode is essentially meant to count occurrences of simple keywords to feed a score and density of a set of keywords. This mode will be preferred when you need to observe and measure frequent use of keywords
- patternGroup: this mode is meant to verify the presence of a keyword or a combination of keywords, eventually within specific contexts (e.g. in specific file extensions, specific file names, etc.). This mode uses regular expressions and will be preferred when you need to observe and detect rare use of keywords
<?xml version="1.0" encoding="utf-8"?>
<UserScan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="KeywordModel.xsd">
<keywordScan name="PII Suspicion" version="1.0">
<keywordGroup name="People" weight="1" sensitive="0" full_word="0" scope="code">
<keywordItem id="1">firstname</keywordItem>
<keywordItem id="2">forename</keywordItem>
<keywordItem id="3">email</keywordItem>
</keywordGroup>
<keywordGroup name="Social Security" weight="10" sensitive="1" full_word="1" scope="comment">
<keywordItem id="4">social security number</keywordItem>
<keywordItem id="5">socialsecuritynumber</keywordItem>
<keywordItem id="6">ssn</keywordItem>
</keywordGroup>
</keywordScan>
<keywordScan name="Malicious Packages">
<patternGroup name="NPM" weight="300" sensitive="0" full_word="1" >
<patterns>
<search id="jsfiles">
<filename>*.js</filename>
</search>
<search id="jsonfiles">
<filename>*.json</filename>
</search>
<search id="npmfiles">
<filename>*.npm</filename>
</search>
<search id="flatmap">
<filename>*.*</filename>
<content>flatmap-stream</content>
</search>
<search id="babelcli">
<filename>*.*</filename>
<content>babelcli</content>
</search>
<search id="gruntcli">
<filename>*.*</filename>
<content>gruntcli</content>
</search>
<search id="nodesass">
<filename>*.*</filename>
<content>nodesass</content>
</search>
</patterns>
<formula value="(jsfiles or jsonfiles or npmfiles) and (flatmap or babelcli or gruntcli or nodesass)"/>
</patternGroup>
</keywordScan>
</UserScan>
C:\Highlight\Highlight-Automation-Command>java -jar HighlightAutomation.jar –sourceDir “C:\sourcecode” –workingDir “C:\sourcecode\HighlightResults” –keywordScan “\\network\path\GPDR_keywords.xml” –skipUpload
When scanning an app with the feature active, the command line will produce one result CSV per keywordScan and per technology (e.g. Java-[date].KeywordScan.GDPR.csv, Java-[date].KeywordScan.Passwords.csv, Python-[date].KeywordScan.GDPR.csv, Python-[date].KeywordScan.Passwords.csv, etc.).
Each produced CSV will contain the list of scanned files as rows and the number of found keyword group occurrences as columns.
Explore the results
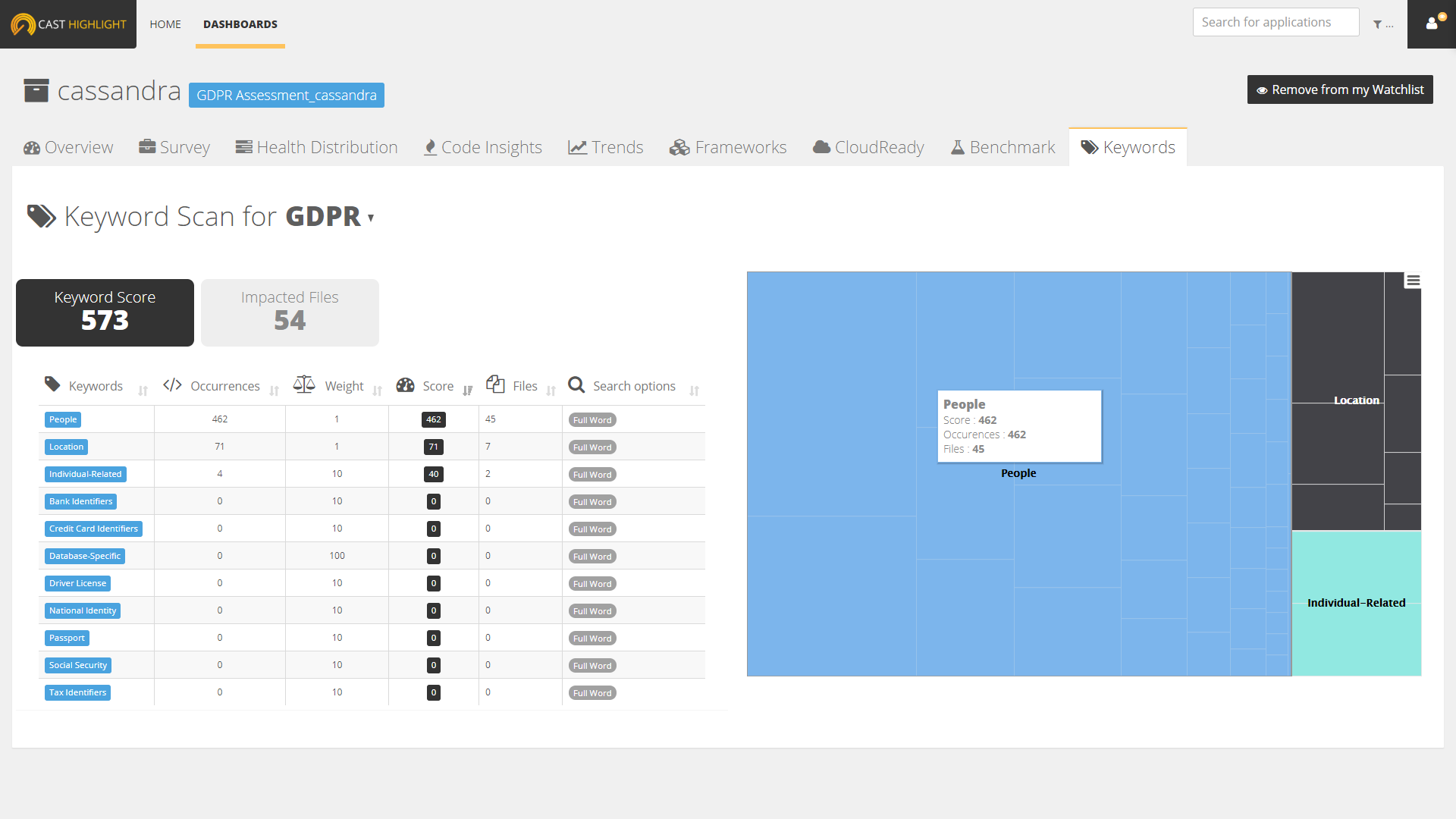
In Highlight dashboards, Keyword Scan information can be visualized at the portfolio level from the menu entry “KEYWORD SCAN”. Using the weights and number of occurrences for a keyword group, the dashboard displays the aggregated scores by domain, application or keywords. Keyword scores are really simple to apprehend as their purpose is to quickly identify the relative volume of occurrences (in regards of keyword severities), density and file scope of a keyword set:
- Score: number of occurrences * weight
- Density: score / total files of the application
- Impacted Files: number of files where keyword occurrences have been found
Visually, you can easily see when applications contain a lot of occurrences and/or occurrences with high severity by looking at the scores (horizontal axis), right side of the chart corresponding to high scores. Depending on your use case, you can also change the vertical axis with the main Highlight KPIs (Business Impact, FTEs, Lines of Code, Cloud readiness, etc.) and see how your application portfolio is distributed on this new metric.
Take concrete actions
In a GDPR assessment context, it also makes sense to leverage one of the feature we introduced in the last version: the capability to filter application results on survey answers.
Create a custom survey and simply ask your application owners the question “Does your application manipulate Personally Identifiable Information?”. Back in the dashboard, select the answer “No” and see if the applications that are supposed to not manipulate PII data, have in fact occurrences on GDPR-related keywords. You now have a solid list of application candidates to investigate for a GPDR registration.